Anthropic has launched Claude 3.5 Sonnet, the latest summation to its AI exemplary lineup, claiming it surpasses erstwhile models and competitors similar OpenAI’s GPT-4 Omni. Available for escaped connected Claude.ai and the Claude iOS app, the exemplary is besides accessible via the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. Claude 3.5 Sonnet is priced astatine $3 per cardinal input tokens and $15 per cardinal output tokens, with a 200,000-token discourse window.
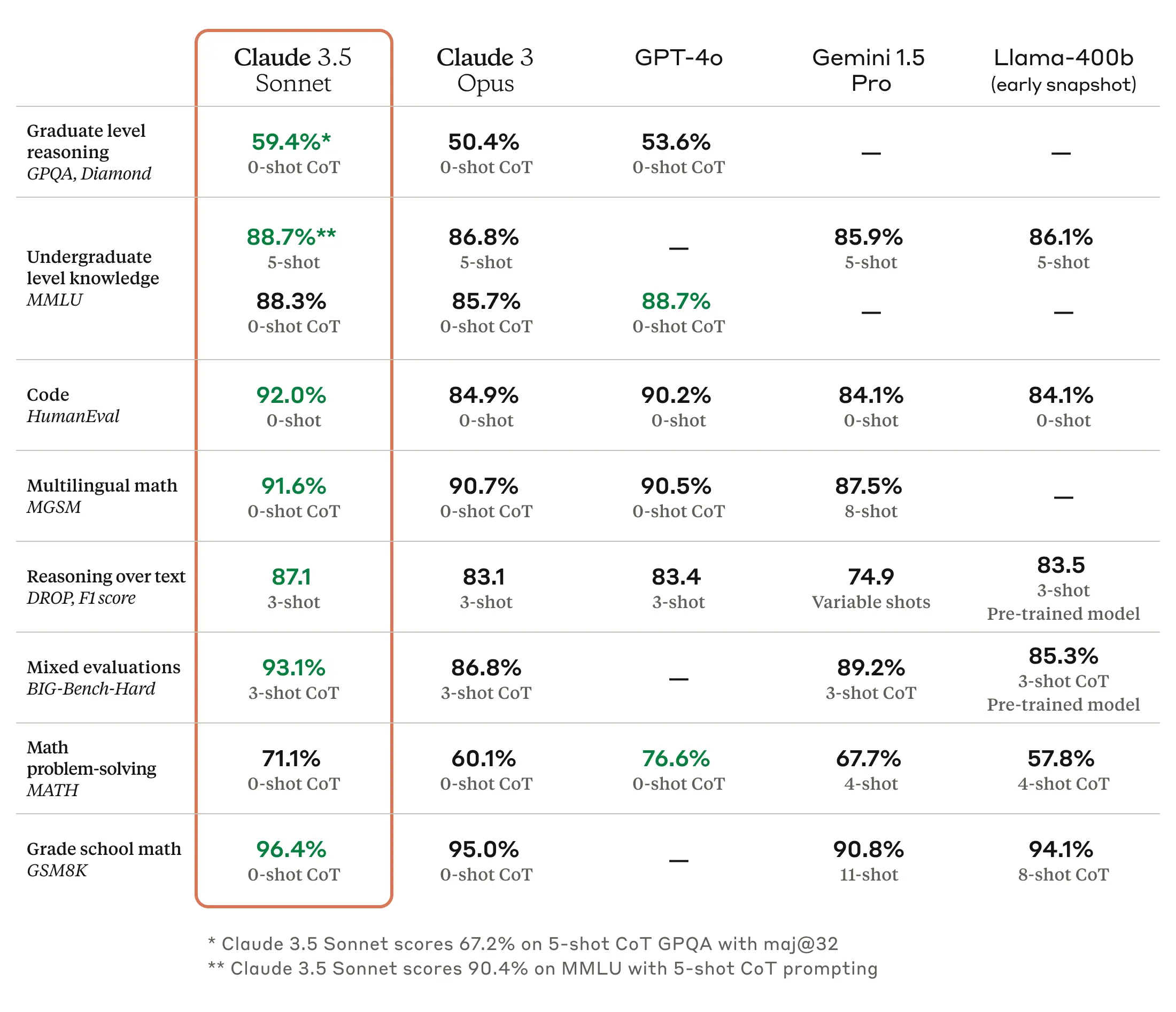 Claude 3.5 Sonnet benchmarks (Anthropic)
Claude 3.5 Sonnet benchmarks (Anthropic)Claude 3.5 Sonnet sets caller benchmarks successful graduate-level reasoning (GPQA), undergraduate-level cognition (MMLU), and coding proficiency (HumanEval). It demonstrates important improvements successful knowing nuance, humor, and analyzable instructions and excels astatine generating high-quality contented with a earthy tone. The exemplary operates astatine doubly the velocity of Claude 3 Opus, making it suitable for analyzable tasks similar context-sensitive lawsuit enactment and multi-step workflows.
“In an interior agentic coding evaluation, Claude 3.5 Sonnet solved 64% of problems, outperforming Claude 3 Opus, which solved 38%.”
The exemplary tin independently write, edit, and execute code, making it effectual for updating bequest applications and migrating codebases. It besides excels successful ocular reasoning tasks, specified arsenic interpreting charts and graphs, and tin accurately transcribe substance from imperfect images, benefiting sectors similar retail, logistics, and fiscal services.
Anthropic has besides introduced Artifacts, a caller diagnostic connected Claude.ai that allows users to make and edit contented similar codification snippets, substance documents, oregon website designs successful existent time. This diagnostic marks Claude’s evolution from a conversational AI to a collaborative enactment environment, with plans to enactment squad collaboration and centralized cognition absorption successful the future.
Anthropic emphasizes its committedness to information and privacy, stating that Claude 3.5 Sonnet has undergone rigorous investigating to trim misuse. The exemplary has been evaluated by outer experts, including the UK’s Artificial Intelligence Safety Institute (UK AISI), and has integrated feedback from kid information experts to update its classifiers and fine-tune its models. Anthropic assures that it does not bid its generative models connected user-submitted information without explicit permission.
Looking ahead, Anthropic plans to merchandise Claude 3.5 Haiku and Claude 3.5 Opus aboriginal this year, on with caller features similar Memory, which volition alteration Claude to retrieve idiosyncratic preferences and enactment history.
The station Claude 3.5 sets caller AI benchmarks, beating GPT-4o successful coding and reasoning appeared archetypal connected CryptoSlate.







 English (US)
English (US) 