Groq’s LPU Inference Engine, a dedicated Language Processing Unit, has acceptable a caller grounds successful processing ratio for ample connection models.
In a caller benchmark conducted by ArtificialAnalysis.ai, Groq outperformed 8 different participants crossed respective cardinal show indicators, including latency vs. throughput and full effect time. Groq’s website states that the LPU’s exceptional performance, peculiarly with Meta AI’s Llama 2-70b model, meant “axes had to beryllium extended to crippled Groq connected the latency vs. throughput chart.”
Per ArtificialAnalysis.ai, the Groq LPU achieved a throughput of 241 tokens per second, importantly surpassing the capabilities of different hosting providers. This level of show is treble the velocity of competing solutions and perchance opens up caller possibilities for ample connection models crossed assorted domains. Groq’s interior benchmarks further emphasized this achievement, claiming to scope 300 tokens per second, a velocity that bequest solutions and incumbent providers person yet to travel adjacent to.
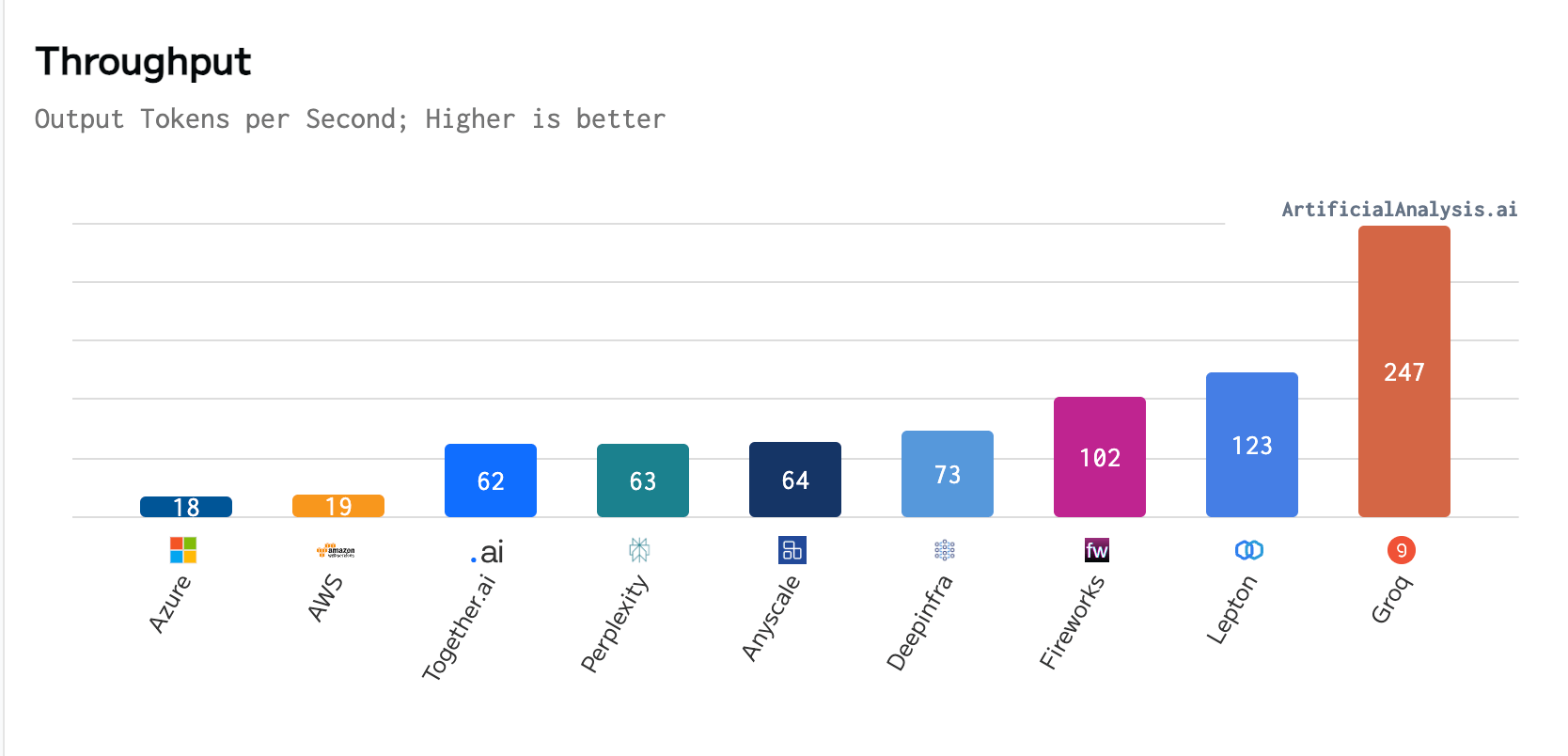 AI tokens per 2nd (Source: artificialanalysis.ai)
AI tokens per 2nd (Source: artificialanalysis.ai)The GroqCard Accelerator, priced astatine $19,948 and readily disposable to consumers, lies astatine the bosom of this innovation. Technically, it boasts up to 750 TOPs (INT8) and 188 TFLOPs (FP16 @900 MHz) successful performance, alongside 230 MB SRAM per spot and up to 80 TB/s on-die representation bandwidth, outperforming accepted CPU and GPU setups, specifically successful LLM tasks. This show leap is attributed to the LPU’s quality to importantly trim computation clip per connection and alleviate outer representation bottlenecks, thereby enabling faster substance series generation.
Accelerator, priced astatine $19,948 and readily disposable to consumers, lies astatine the bosom of this innovation. Technically, it boasts up to 750 TOPs (INT8) and 188 TFLOPs (FP16 @900 MHz) successful performance, alongside 230 MB SRAM per spot and up to 80 TB/s on-die representation bandwidth, outperforming accepted CPU and GPU setups, specifically successful LLM tasks. This show leap is attributed to the LPU’s quality to importantly trim computation clip per connection and alleviate outer representation bottlenecks, thereby enabling faster substance series generation.
 Groq LPU card
Groq LPU cardComparing the Groq LPU paper to NVIDIA’s flagship A100 GPU of akin cost, the Groq paper is superior successful tasks wherever velocity and ratio successful processing ample volumes of simpler information (INT8) are critical, adjacent erstwhile the A100 uses precocious techniques to boost its performance. However, erstwhile handling much analyzable information processing tasks (FP16), which necessitate greater precision, the Groq LPU doesn’t scope the show levels of the A100.
Essentially, some components excel successful antithetic aspects of AI and ML computations, with the Groq LPU paper being exceptionally competitory successful moving LLMS astatine velocity portion the A100 leads elsewhere. Groq is positioning the LPU arsenic a instrumentality for moving LLMs alternatively than earthy compute oregon fine-tuning models.
Querying Groq’s Llama 70b exemplary connected its website resulted successful the pursuing response, which was processed astatine 420 tokens per second;
“Groq is simply a almighty instrumentality for moving instrumentality learning models, peculiarly successful accumulation environments. While it whitethorn not beryllium the champion prime for exemplary tuning oregon training, it excels astatine executing pre-trained models with precocious show and debased latency.”
A nonstop examination of representation bandwidth is little straightforward owed to the Groq LPU’s absorption connected on-die representation bandwidth, importantly benefiting AI workloads by reducing latency and expanding information transportation rates wrong the chip.
Evolution of machine components for AI and instrumentality learning
The instauration of the Language Processing Unit by Groq could beryllium a milestone successful the improvement of computing hardware. Traditional PC components—CPU, GPU, HDD, and RAM—have remained comparatively unchanged successful their basal signifier since the instauration of GPUs arsenic chiseled from integrated graphics. The LPU introduces a specialized attack focused connected optimizing the processing capabilities of LLMs, which could go progressively advantageous to tally connected section devices. While services similar ChatGPT and Gemini tally done unreality API services, the benefits of onboard LLM processing for privacy, efficiency, and information are countless.
GPUs, initially designed to offload and accelerate 3D graphics rendering, person go a captious constituent successful processing parallel tasks, making them indispensable successful gaming and technological computing. Over time, the GPU’s relation expanded into AI and instrumentality learning, courtesy of its quality to execute concurrent operations. Despite these advancements, the cardinal architecture of these components chiefly stayed the same, focusing connected general-purpose computing tasks and graphics rendering.
The advent of Groq’s LPU Inference Engine represents a paradigm displacement specifically engineered to code the unsocial challenges presented by LLMs. Unlike CPUs and GPUs, which are designed for a wide scope of applications, the LPU is tailor-made for the computationally intensive and sequential quality of connection processing tasks. This absorption allows the LPU to surpass the limitations of accepted computing hardware erstwhile dealing with the circumstantial demands of AI connection applications.
One of the cardinal differentiators of the LPU is its superior compute density and representation bandwidth. The LPU’s plan enables it to process substance sequences overmuch faster, chiefly by reducing the clip per connection calculation and eliminating outer representation bottlenecks. This is simply a captious vantage for LLM applications, wherever rapidly generating substance sequences is paramount.
Unlike accepted setups wherever CPUs and GPUs trust connected outer RAM for memory, on-die representation is integrated straight into the spot itself, offering importantly reduced latency and higher bandwidth for information transfer. This architecture allows for accelerated entree to data, important for the processing ratio of AI workloads, by eliminating the time-consuming trips information indispensable marque betwixt the processor and abstracted representation modules. The Groq LPU’s awesome on-die representation bandwidth of up to 80 TB/s showcases its quality to grip the immense information requirements of ample connection models much efficiently than GPUs, which mightiness boast precocious off-chip representation bandwidth but cannot lucifer the velocity and ratio provided by the on-die approach.
Creating a processor designed for LLMs addresses a increasing request wrong the AI probe and improvement assemblage for much specialized hardware solutions. This determination could perchance catalyze a caller question of innovation successful AI hardware, starring to much specialized processing units tailored to antithetic aspects of AI and instrumentality learning workloads.
As computing continues to evolve, the instauration of the LPU alongside accepted components similar CPUs and GPUs signals a caller signifier successful hardware development—one that is progressively specialized and optimized for the circumstantial demands of precocious AI applications.
The station Groq $20,000 LPU paper breaks AI show records to rival GPU-led industry appeared archetypal connected CryptoSlate.








 English (US)
English (US) 